Designing an Integration Runtime for
Safe Production Workflows
CLIENT
: Personal / Conceptual Project
PRODUCT
: : Integration Runtime Platform (SaaS)
DURATION
: 2 Weeks
CAPACITY
: Sole Product Designer
TEAM MODEL
: Independent
STATUS
: Concept · Not Shipped
IN A NUTSHELL
A production-grade integration runtime that makes execution state visible, failures diagnosable, and recovery safe — without exposing configuration under stress.
IMPACT
Failures surface as diagnosable states — not generic errors.
Recovery paths scoped to the active issue — config stays untouched.
Runtime state visible at all times — no guesswork under pressure.
Platform UX
Reliability Systems
Failure Recovery
The Problem
Integrations don't fail loudly. They degrade quietly
Auditing existing integration dashboards across tools like Zapier, Workato, and Make revealed the same pattern: failures were either buried in logs or collapsed into a generic “Something went wrong” state. There was no way to understand severity, scope, or safe next action from the interface alone.
The deeper issue wasn't missing information — it was missing structure. Admins had data, but no way to reason about it under pressure.
The real risk:
When admins can't diagnose a failure quickly, their first instinct is to edit configuration. That instinct — completely understandable — is also the most common way a single failure becomes three.
What I Tried First
The notification model didn't work
The first direction was alert-based
Surface failures as notifications with severity levels, let admins click through to investigate. It felt familiar and low-friction.
The problem
Notifications are optimized for awareness, not action. They tell you something is wrong — but not what it means, what's safe to do, or whether it's already being handled. Admins still had to navigate to config to understand the situation. Under pressure, that extra step is where mistakes happen.
Pivot:
The interface needed to be built around execution state — not events.
State is always current, always actionable, and naturally constrains what's available without needing a separate permission layer.
The Shift
From configuration tool to operational system
Before
After
Failures buried in logs or raw traces
Failures as structured, diagnosable objects
Generic error states with no context
Execution state always visible and current
Recovery and config on the same surface
Recovery scoped to the active issue only
Admins guessing what's safe to touch
Safe actions determined by system state

Design Decisions
Four decisions. Each with a cost
01 — State as the entry point
Surface execution state first — Running, Degraded, Paused, Rate-limited.
State governs which actions appear. Unsafe options are never shown, not just disabled.
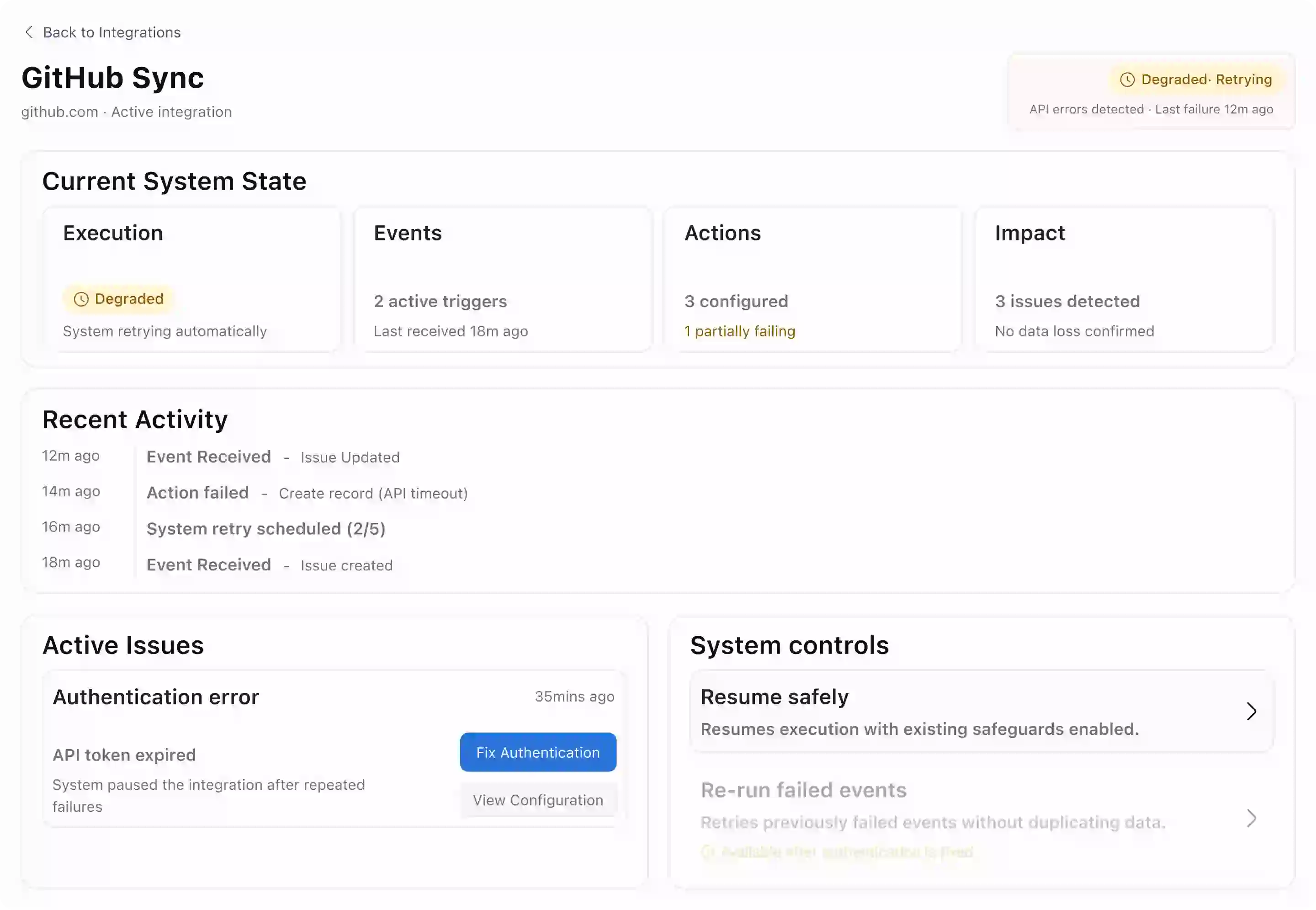
This removed flexibility some admins want — like force-resuming a paused integration. That tension was intentional. Confidence matters more than speed in a failure scenario.
02 — Failures as structured objects
Each failure surfaces: what failed, why, what's affected, and whether data loss occurred. No log access required to understand the incident.
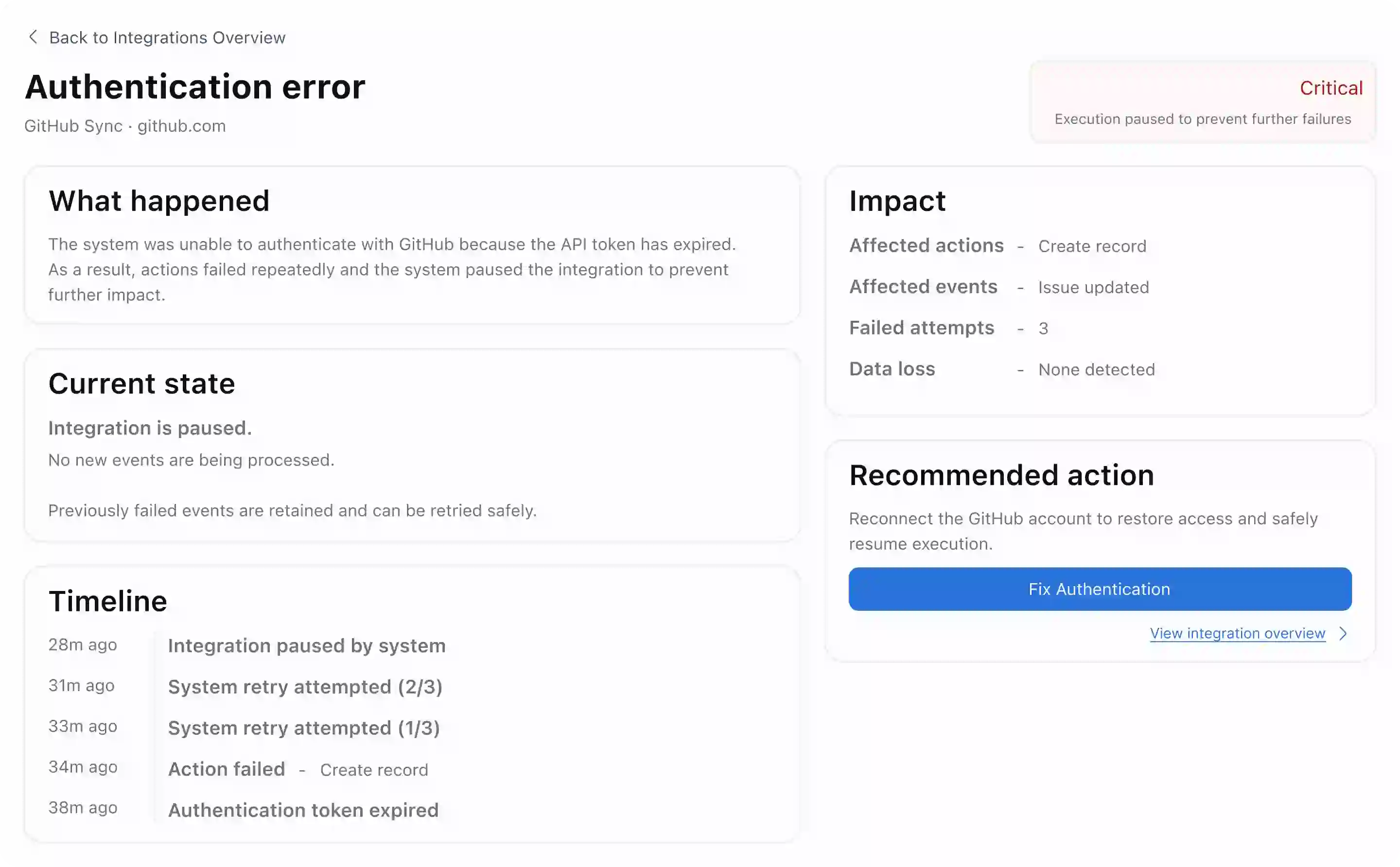
Structuring failures meant making assumptions about failure types. Novel or compound failures may not fit cleanly — a known gap that needs a fallback pattern in production.
03 — Constrained recovery paths
Recovery flows are issue-specific. Reconnecting auth doesn't expose trigger config. Retrying events doesn't allow editing actions. Each path addresses exactly one failure.

Power users wanted more control. The constraint held because most errors during incidents come from over-intervention — not under-action.
04 — Configuration read-only by default
Production config defaults to inspection. An explicit action is required to enter edit mode, visually separated from all recovery flows.

Adds one extra step for legitimate config changes. A small cost that creates a clear break between fixing a failure and changing how the system works.
Outcomes
What changed
Four things that were broken. Four things that aren’t anymore.
No guesswork
Execution state and failure cause visible before any action is taken.
Scoped recovery
Each fix flow addresses one issue — config remains untouched.
Auto-contained
Repeated failures trigger system pause before data is at risk.
Full audit trail
Every action logged immutably, system and human. If something goes wrong again, the record is already there.
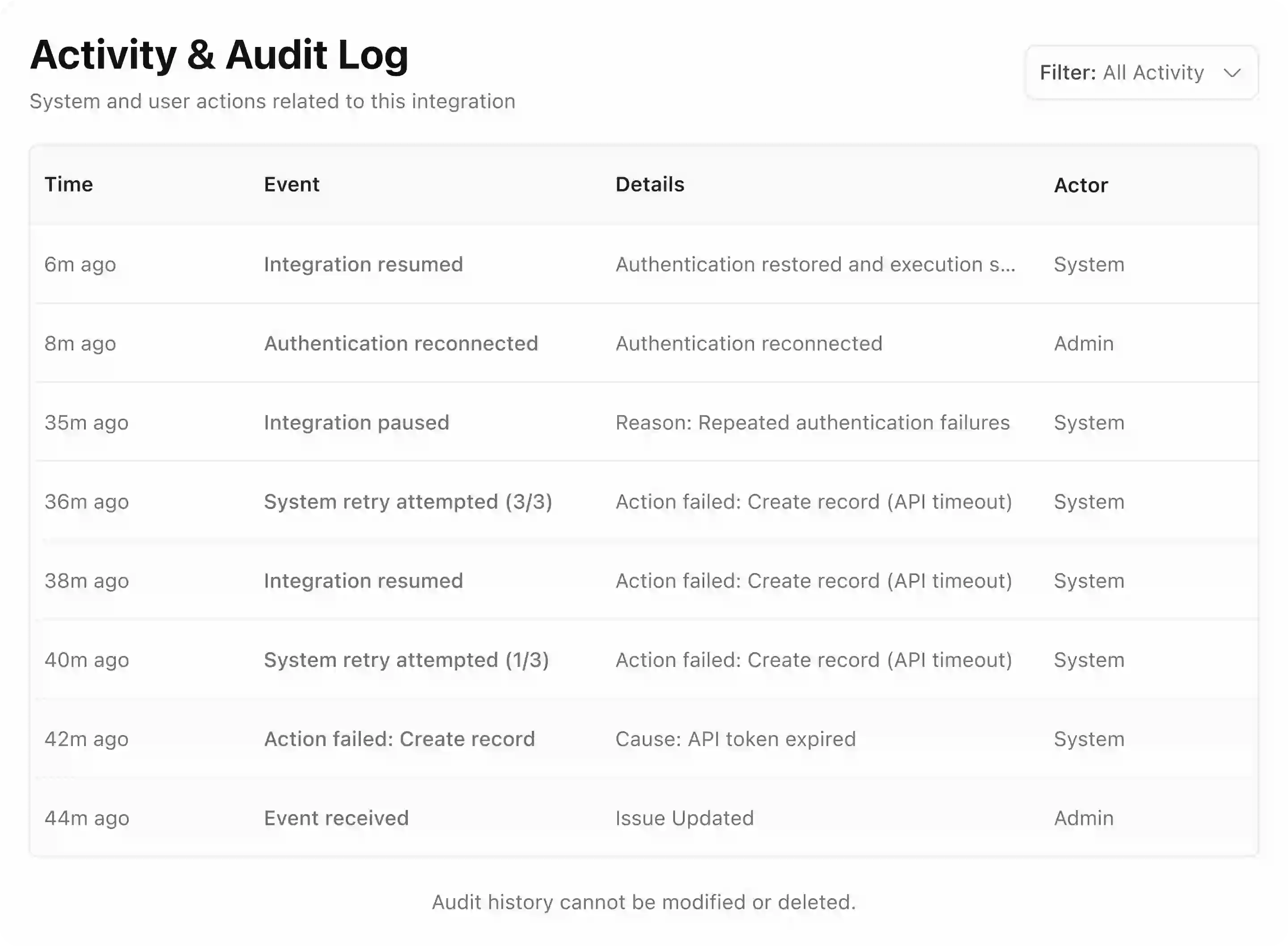
Learnings
Where I'd push further
The constrained recovery model holds well for known failure types. The open question is compound failures, where multiple causes are active simultaneously and no single fix flow applies.
I'd test a “safe mode” fallback: a minimal surface that pauses everything, logs state, and lets engineering take over without the admin needing to decide anything.
What I learned most
The most impactful decisions here weren't about what to add — they were about what to remove. Every option that felt helpful in a calm moment became a liability the moment pressure was high.
Always happy to talk about thoughtful product work.
CHAOS
→
CLARITY
Resume
V
I
S
W
A